
Analysis Grand Challenge Documentation#
![]()
![]()
Introduction#
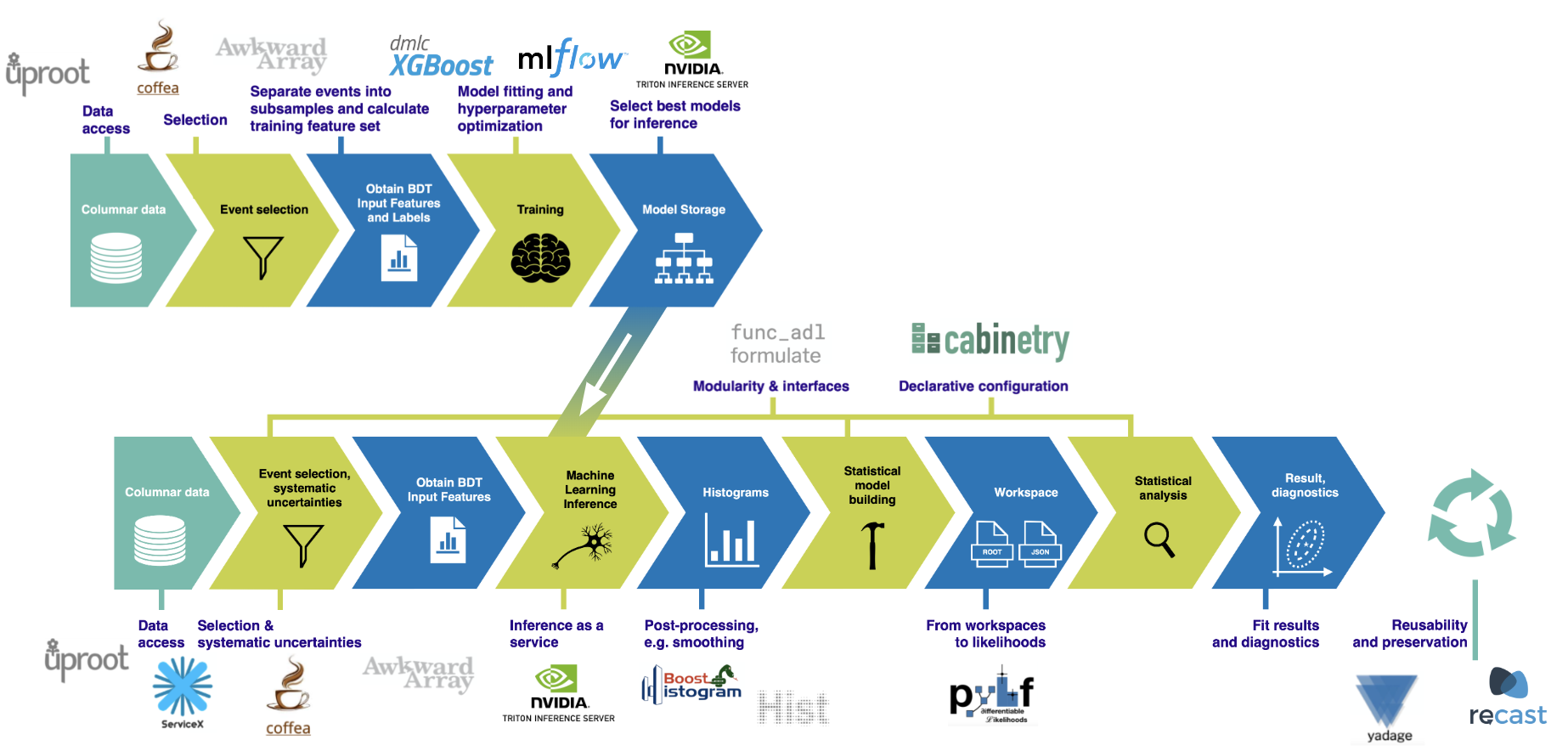
The Analysis Grand Challenge (AGC) is about performing the last steps in an analysis pipeline at scale to test workflows envisioned for the HL-LHC. This includes
columnar data extraction from large datasets,
processing of that data (event filtering, construction of observables, evaluation of systematic uncertainties) into histograms,
statistical model construction and statistical inference,
relevant visualizations for these steps,
all done in a reproducible & preservable way that can scale to HL-LHC requirements.
The AGC has two major pieces:
specification of a physics analysis using Open Data which captures relevant workflow aspects encountered in physics analyses performed at the LHC,
a reference implementation demonstrating the successful execution of this physics analysis at scale.
The physics analysis task is a \(t\bar{t}\) cross-section measurement with 2015 CMS Open Data (see datasets/cms-open-data-2015). The current reference implementation can be found in analyses/cms-open-data-ttbar. In addition to this, analyses/atlas-open-data-hzz contains a smaller scale \(H\rightarrow ZZ^*\) analysis based on ATLAS Open Data.
More information & references#
The AGC website contains more information about the AGC.
The project has been described in a few conference proceedings. If you make use of the AGC in your research, please consider citing the project. We recommend citing the 2022 ICHEP proceedings when referring to the project more generally and the other other publications as relevant to the specific context.
ICHEP 2022 proceedings with a general introduction: DOI: 10.22323/1.414.0235, INSPIRE
ACAT 2022 proceedings with first performance measurements: IOP Conference Series publication forthcoming, arXiv:2304.05214 [hep-ex], INSPIRE
CHEP 2023 procedings with an overview: DOI: 10.1051/epjconf/202429506016, INSPIRE
CHEP 2023 procedings focused on ML task: DOI: 10.1051/epjconf/202429508011, INSPIRE
Additional information is available in a series of AGC-focused workshops:
We also have a dedicated IRIS-HEP webpage.
AGC and IRIS-HEP#
The AGC serves as an integration exercise for IRIS-HEP, allowing the testing of new services, libraries and workflows on dedicated analysis facilities in the context of realistic physics analyses.
AGC and you#
We believe that the AGC can be useful in various contexts:
testbed for software library development,
realistic environment to prototype analysis workflows,
functionality, integration & performance test for analysis facilities.
We are very interested in seeing (parts of) the AGC implemented in different ways. Please get in touch if you have investigated other approaches you would like to share! There is no need to implement the full analysis task — it splits into pieces (for example the production of histograms) that can also be tackled individually.
More details: what is being investigated in the AGC context#
New user interfaces: Complementary services that present the analyst with a notebook-based interface. Example software: Jupyter.
Data access: Services that provide quick access to the experiment’s official data sets, often allowing simple derivations and local caching for efficient access. Example software and services:
Rucio,ServiceX,SkyHook,iDDS,RNTuple.Event selection: Systems/frameworks allowing analysts to process entire datasets, select desired events, and calculate derived quantities. Example software and services:
coffea,awkward-array,func_adl,RDataFrame.Histogramming and summary statistics: Closely tied to the event selection, histogramming tools provide physicists with the ability to summarize the observed quantities in a dataset. Example software and services:
coffea,func_adl,cabinetry,hist.Statistical model building and fitting: Tools that translate specifications for event selection, summary statistics, and histogramming quantities into statistical models, leveraging the capabilities above, and perform fits and statistical analysis with the resulting models. Example software and services:
cabinetry,pyhf,FuncX+pyhffitting serviceReinterpretation / analysis preservation: Standards for capturing the entire analysis workflow, and services to reuse the workflow which enables reinterpretation. Example software and services:
REANA,RECAST.
Acknowledgements#
This work was supported by the U.S. National Science Foundation (NSF) cooperative agreements OAC-1836650 and PHY-2323298 (IRIS-HEP).
ttbar with CMS Open Data